MAny: Merge Anything for Multimodal Continual Instruction Tuning
MAny: Merge Anything for Multimodal Continual Instruction Tuning
Zijian Gao, Wangwang Jia, Xingxing Zhang, Pengfei Qian, Tao Sun, Bo Ding, Yong Dou, Huaimin Wang, Kele Xu
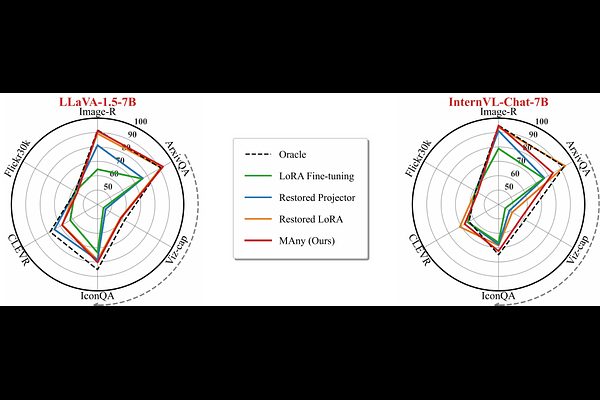
AbstractMultimodal Continual Instruction Tuning (MCIT) is essential for sequential task adaptation of Multimodal Large Language Models (MLLMs) but is severely restricted by catastrophic forgetting. While existing literature focuses on the reasoning language backbone, in this work, we expose a critical yet neglected dual-forgetting phenomenon across both perception drift in Cross-modal Projection Space and reasoning collapse in Low-rank Parameter Space. To resolve this, we present \textbf{MAny} (\textbf{M}erge \textbf{Any}thing), a framework that merges task-specific knowledge through \textbf{C}ross-modal \textbf{P}rojection \textbf{M}erging (\textbf{CPM}) and \textbf{L}ow-rank \textbf{P}arameter \textbf{M}erging (\textbf{LPM}). Specifically, CPM recovers perceptual alignment by adaptively merging cross-modal visual representations via visual-prototype guidance, ensuring accurate feature recovery during inference. Simultaneously, LPM eliminates mutual interference among task-specific low-rank modules by recursively merging low-rank weight matrices. By leveraging recursive least squares, LPM provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability. Notably, MAny operates as a training-free paradigm that achieves knowledge merging via efficient CPU-based algebraic operations, eliminating additional gradient-based optimization beyond initial tuning. Our extensive evaluations confirm the superior performance and robustness of MAny across multiple MLLMs and benchmarks. Specifically, on the UCIT benchmark, MAny achieves significant leads of up to 8.57\% and 2.85\% in final average accuracy over state-of-the-art methods across two different MLLMs, respectively.