Teaching Time Series to See and Speak: Forecasting with Aligned Visual and Textual Perspectives
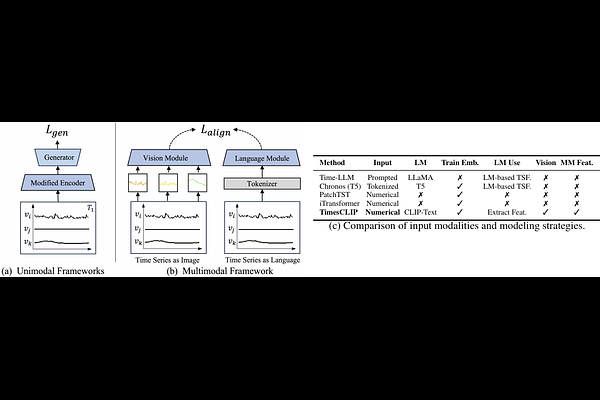
Teaching Time Series to See and Speak: Forecasting with Aligned Visual and Textual Perspectives
Dong Sixun, Fan Wei, Teresa Wu, Fu Yanjie
AbstractTime series forecasting traditionally relies on unimodal numerical inputs, which often struggle to capture high-level semantic patterns due to their dense and unstructured nature. While recent approaches have explored representing time series as text using large language models (LLMs), these methods remain limited by the discrete nature of token sequences and lack the perceptual intuition humans typically apply, such as interpreting visual patterns. In this paper, we propose a multimodal contrastive learning framework that transforms raw time series into structured visual and textual perspectives. Rather than using natural language or real-world images, we construct both modalities directly from numerical sequences. We then align these views in a shared semantic space via contrastive learning, enabling the model to capture richer and more complementary representations. Furthermore, we introduce a variate selection module that leverages the aligned representations to identify the most informative variables for multivariate forecasting. Extensive experiments on fifteen short-term and six long-term forecasting benchmarks demonstrate that our approach consistently outperforms strong unimodal and cross-modal baselines, highlighting the effectiveness of multimodal alignment in enhancing time series forecasting. Code is available at: https://github.com/Ironieser/TimesCLIP.