R-APS: Compositional Reasoning and In-Context Meta-Learning for Constrained Design via Reflective Adversarial Pareto Search
R-APS: Compositional Reasoning and In-Context Meta-Learning for Constrained Design via Reflective Adversarial Pareto Search
João Pedro Gandarela, Thiago Rios, Stefan Menzel, André Freitas
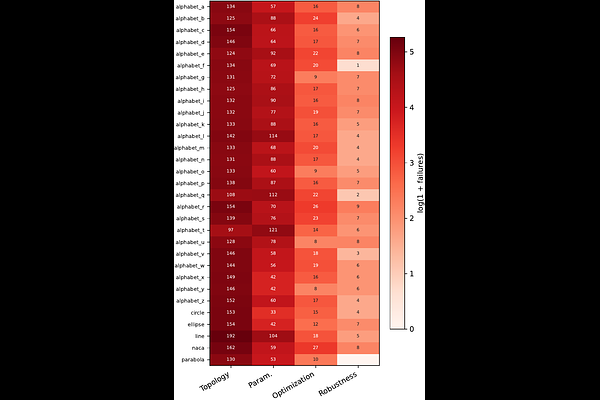
AbstractLarge language models (LLMs) are fluent on open-ended tasks, yet in agentic settings, where a system must plan, use tools, and act over extended horizons, fluency does not ensure reliable delivery. We trace this gap to three coupled structural failures: errors propagate without localization, worst-case perturbations go unevaluated, and accumulated knowledge is never invalidated. We argue these share a root cause: abductive, counterfactual, meta-inductive, corrective, and inductive reasoning pull a shared context in incompatible directions. We introduce Reflective Adversarial Pareto Search (R-APS), to our knowledge the first method addressing all three failures jointly via reasoning-mode decomposition, allocating each reasoning mode its own context and orchestrating interaction across three timescales: staged compositional reasoning with a typed validation critic (failure localization), sensitivity-guided counterfactual stress-testing as a first-class Pareto objective (robustness), and meta-inductive rule extraction with explicit invalidation (persistent memory). R-APS requires no fine-tuning and operates on a frozen LLM purely via structured protocol design. We evaluate on planar mechanism synthesis (robotics, prosthetics, mechanical design), with every candidate checked by a kinematic solver. On 32 target trajectories, R-APS delivers robustness certificates 3.5x tighter than uniform-perturbation baselines, 46% faster iterations-to-first-admission, and 2.1x Chamfer-distance reduction over Enum+GA while jointly controlling bar-count and worst-case robustness. Small 4B reasoning-specialized models prove competitive with general-purpose 70B backbones inside the protocol, suggesting structured protocols can partially offset model scale.