Strait: Perceiving Priority and Interference in ML Inference Serving
Strait: Perceiving Priority and Interference in ML Inference Serving
Haidong Zhao, Nikolaos Georgantas
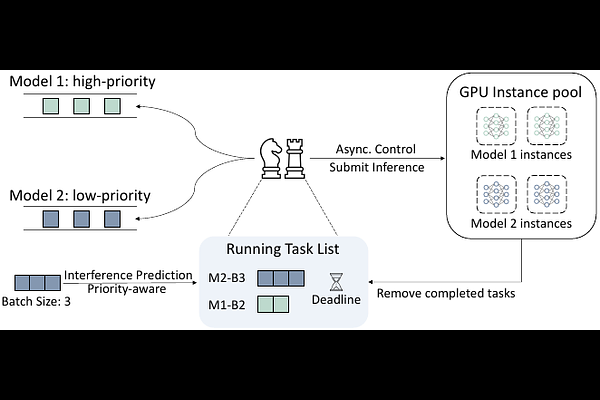
AbstractMachine learning (ML) inference serving systems host deep neural network (DNN) models and schedule incoming inference requests across deployed GPUs. However, limited support for task prioritization and insufficient latency estimation under concurrent execution may restrict their applicability in on-premises scenarios. We present \emph{Strait}, a serving system designed to enhance deadline satisfaction for dual-priority inference traffic under high GPU utilization. To improve latency estimation, Strait models potential contention during data transfer and accounts for kernel execution interference through an adaptive prediction model. By drawing on these predictions, it performs priority-aware scheduling to deliver differentiated handling. Evaluation results under intense workloads suggest that Strait reduces deadline violations for high-priority tasks by 1.02 to 11.18 percentage points while incurring acceptable costs on low-priority tasks. Compared to software-defined preemption approaches, Strait also exhibits more equitable performance.