Online Learning and Equilibrium Computation with Ranking Feedback
Online Learning and Equilibrium Computation with Ranking Feedback
Mingyang Liu, Yongshan Chen, Zhiyuan Fan, Gabriele Farina, Asuman Ozdaglar, Kaiqing Zhang
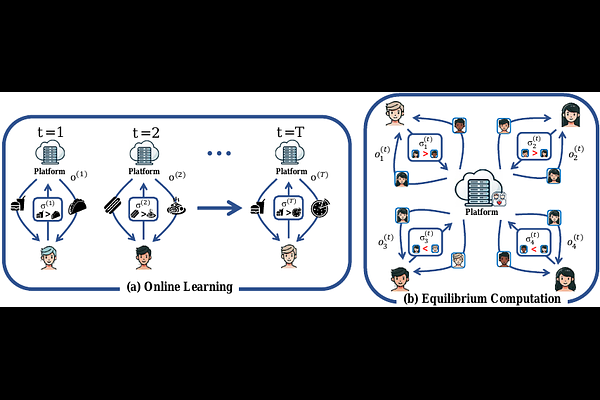
AbstractOnline learning in arbitrary, and possibly adversarial, environments has been extensively studied in sequential decision-making, and it is closely connected to equilibrium computation in game theory. Most existing online learning algorithms rely on \emph{numeric} utility feedback from the environment, which may be unavailable in human-in-the-loop applications and/or may be restricted by privacy concerns. In this paper, we study an online learning model in which the learner only observes a \emph{ranking} over a set of proposed actions at each timestep. We consider two ranking mechanisms: rankings induced by the \emph{instantaneous} utility at the current timestep, and rankings induced by the \emph{time-average} utility up to the current timestep, under both \emph{full-information} and \emph{bandit} feedback settings. Using the standard external-regret metric, we show that sublinear regret is impossible with instantaneous-utility ranking feedback in general. Moreover, when the ranking model is relatively deterministic, \emph{i.e.}, under the Plackett-Luce model with a temperature that is sufficiently small, sublinear regret is also impossible with time-average utility ranking feedback. We then develop new algorithms that achieve sublinear regret under the additional assumption that the utility sequence has sublinear total variation. Notably, for full-information time-average utility ranking feedback, this additional assumption can be removed. As a consequence, when all players in a normal-form game follow our algorithms, repeated play yields an approximate coarse correlated equilibrium. We also demonstrate the effectiveness of our algorithms in an online large-language-model routing task.