Calibration, Not Compilation: Detecting and Repairing Misspecified Probabilistic Programs Written by Language Models
Calibration, Not Compilation: Detecting and Repairing Misspecified Probabilistic Programs Written by Language Models
Jian Xu, Delu Zeng, John Paisley, Qibin Zhao
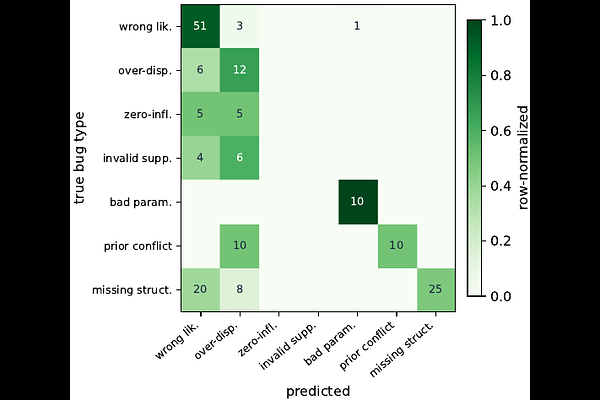
AbstractLanguage models increasingly write probabilistic programs (in NumPyro, Stan, or Pyro), but a program that compiles, runs, and passes every unit test can still be \emph{statistically} wrong -- a Gaussian likelihood for heavy-tailed data, a Poisson for over-dispersed counts, an invalid prior support, or a pathological parameterization. The right verifier is therefore not a test suite but the Bayesian workflow itself: posterior predictive checks, simulation-based calibration, sampler diagnostics ($\hat R$, divergences, ESS), and held-out predictive density. We study this calibration oracle along three axes. \textbf{Detection:} on a benchmark of $14$ misspecification types across $10$ model families ($200$ instances), it flags the bug with AUC $0.97$ ($88\%$ at $2\%$ FPR \emph{when handed the correct reference program, an upper bound}) -- and a fully \emph{reference-free} version that uses no correct program reaches $62$--$78\%$ (the upper figure from a small automated model search), versus $0\%$ for a unit-test oracle. \textbf{Repair:} used as feedback in an LLM repair loop across fifteen models, calibration significantly outperforms unit-test feedback -- which is itself \emph{significantly worse than no feedback at all}, a passing test inducing false confidence that suppresses repair -- and improves over no feedback on strong-but-unsaturated models (GPT-5.1 $33{\to}92\%$, Claude $75{\to}100\%$; paired McNemar, $n{=}228$). \textbf{Reality:} on programs LLMs write from scratch for neutral briefs, $15$--$47\%$ of runnable ones are statistically misspecified (unit tests catch none), and calibration-guided repair significantly beats LLM-as-judge review, a Bayesian-workflow checklist, and data-summary self-debug. Across all three, the lesson is the same: for probabilistic programs, correctness is calibration, not compilation.