ReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models
ReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models
Andre He, Nathaniel Weir, Kaj Bostrom, Allen Nie, Darion Cassel, Sam Bayless, Huzefa Rangwala
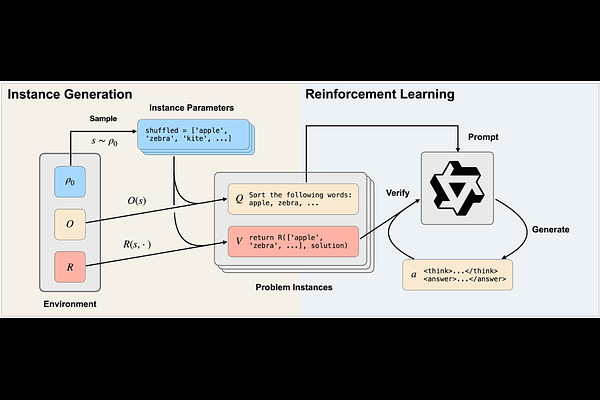
AbstractReinforcement learning with verifiable rewards (RLVR) has emerged as a promising approach for training reasoning language models (RLMs) by leveraging supervision from verifiers. Although verifier implementation is easier than solution annotation for many tasks, existing synthetic data generation methods remain largely solution-centric, while verifier-based methods rely on a few hand-crafted procedural environments. In this work, we scale RLVR by introducing ReSyn, a pipeline that generates diverse reasoning environments equipped with instance generators and verifiers, covering tasks such as constraint satisfaction, algorithmic puzzles, and spatial reasoning. A Qwen2.5-7B-Instruct model trained with RL on ReSyn data achieves consistent gains across reasoning benchmarks and out-of-domain math benchmarks, including a 27\% relative improvement on the challenging BBEH benchmark. Ablations show that verifier-based supervision and increased task diversity both contribute significantly, providing empirical evidence that generating reasoning environments at scale can enhance reasoning abilities in RLMs