ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
Zexi Liu, Jingyi Chai, Xinyu Zhu, Shuo Tang, Rui Ye, Bo Zhang, Lei Bai, Siheng Chen
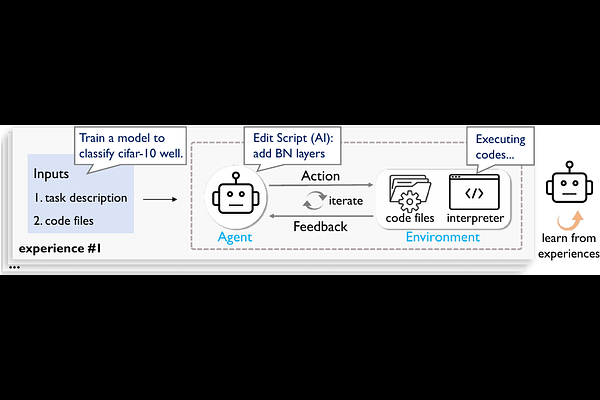
AbstractThe emergence of large language model (LLM)-based agents has significantly advanced the development of autonomous machine learning (ML) engineering. However, most existing approaches rely heavily on manual prompt engineering, failing to adapt and optimize based on diverse experimental experiences. Focusing on this, for the first time, we explore the paradigm of learning-based agentic ML, where an LLM agent learns through interactive experimentation on ML tasks using online reinforcement learning (RL). To realize this, we propose a novel agentic ML training framework with three key components: (1) exploration-enriched fine-tuning, which enables LLM agents to generate diverse actions for enhanced RL exploration; (2) step-wise RL, which enables training on a single action step, accelerating experience collection and improving training efficiency; (3) an agentic ML-specific reward module, which unifies varied ML feedback signals into consistent rewards for RL optimization. Leveraging this framework, we train ML-Agent, driven by a 7B-sized Qwen-2.5 LLM for autonomous ML. Remarkably, despite being trained on merely 9 ML tasks, our 7B-sized ML-Agent outperforms the 671B-sized DeepSeek-R1 agent. Furthermore, it achieves continuous performance improvements and demonstrates exceptional cross-task generalization capabilities.