Transformers Provably Learn to Internalize Chain-of-Thought
Transformers Provably Learn to Internalize Chain-of-Thought
Yixiao Huang, Hanlin Zhu, Zixuan Wang, Jiantao Jiao, Stuart Russell, Somayeh Sojoudi, Song Mei
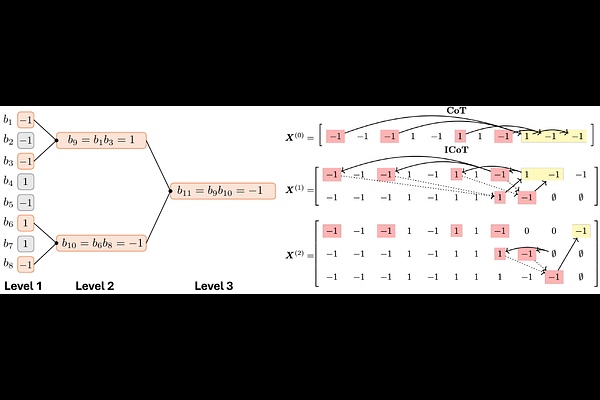
AbstractChain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states, but its theoretical foundations remain poorly understood. We give the first theoretical analysis of ICoT, proving that an $L$-layer transformer trained under our proposed Log-ICoT curriculum learns $k$-parity with $\mathsf{poly}(n)$ samples and $L = \log_2 k$ training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in $k$ to logarithmic. Experiments on multi-layer transformers confirm the theory and visualize how reasoning is progressively absorbed into deeper layers.