Re-mixing Embeddings for Patient Augmentation in Data Scarce Multiple Instance Learning
Re-mixing Embeddings for Patient Augmentation in Data Scarce Multiple Instance Learning
Muhammed Furkan Dasdelen, Fatih Ozlugedik, Anastasia Litinetskaya, Nassir Navab, Carsten Marr, Ario Sadafi
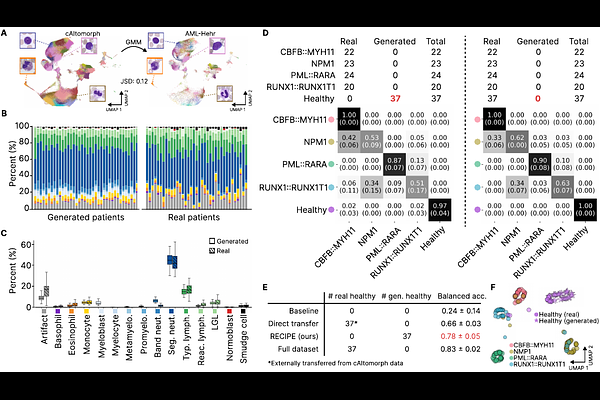
AbstractData scarcity is a major bottleneck in medical Multiple Instance Learning (MIL), especially for rare diseases or expensive modalities. We introduce a statistically grounded patient augmentation approach that generates realistic patients directly in embedding space. Using Gaussian Mixture Models as a probabilistic clustering approach on pooled instance embeddings from all patients, our method learns disease-specific "recipes"-statistical distributions of instances across unsupervised clusters. New patients are then generated by sampling embeddings from clusters based on learned recipes. Unlike existing methods that require examples from all categories, our method can generate patients offline by re-mixing pooled embeddings. Generated patients are further selected based on uncertainty quantification to improve MIL performance. We evaluate our method across three clinically relevant scarcity scenarios: (i) cross-dataset transfer, where an entirely missing "healthy" class is generated using statistics from an external cohort; (ii) low-data regimes, where class sizes are extremely limited; and (iii) small-cohort non-image tasks, including single-cell RNA-seq and flow cytometry. Across all experiments, our method improves performance over baseline, often outperforming other bag-mixing strategies. Notably, in the missing-class scenario, a performance comparable to full-dataset training is achieved, demonstrating its potential for rare disease diagnostic and privacy-preserving patient augmentation. The code is available at https://github.com/marrlab/RECIPE