Train-before-Test Harmonizes Language Model Rankings
Train-before-Test Harmonizes Language Model Rankings
Guanhua Zhang, Ricardo Dominguez-Olmedo, Moritz Hardt
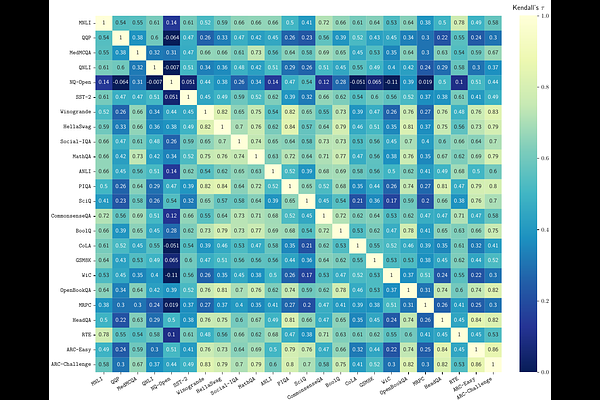
AbstractExisting language model benchmarks provide contradictory model rankings, even for benchmarks that aim to capture similar skills. This dilemma of conflicting rankings hampers model selection, clouds model comparisons, and adds confusion to a growing ecosystem of competing models. Recent work attributed ranking disagreement to the phenomenon of training on the test task: As released, different models exhibit a different level of preparation for any given test task. A candidate solution to the problem is train-before-test: Give each model the same benchmark-specific finetuning before evaluation. Our primary contribution is a broad empirical evaluation of train-before-test across 24 benchmarks and 61 models. We show that train-before-test significantly improves ranking agreement consistently across all benchmarks. Whereas rankings have little external validity to start with, they enjoy a significant degree of external validity when applying train-before-test: Model rankings transfer gracefully from one benchmark to the other. Even within the same model family, train-before-test reduces strong ranking disagreement to near-perfect agreement. In addition, train-before-test reduces the model-score matrix to essentially rank one, revealing new insights into the latent factors of benchmark performance. Our work supports the recommendation to make train-before-test a default component of LLM benchmarking.