Policy and World Modeling Co-Training for Language Agents
Policy and World Modeling Co-Training for Language Agents
Ning Lu, Baijiong Lin, Shengcai Liu, Jiahao Wu, Haoze Lv, Yanbin Wei, Lingting Zhu, Shengju Qian, Xin Wang, Ying-Cong Chen, Qi Wang, Ke Tang
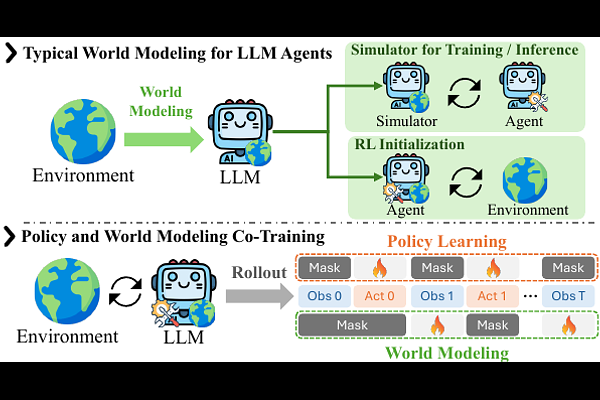
AbstractReinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment. World modeling (WM) can fill this gap, yet existing approaches often require separate simulators, extra training stages, or additional inference-time computation. We observe that on-policy RL rollouts already contain the needed signal: each transition pairs an action with its resulting next observation. Based on this observation, we propose PaW, a Policy and World modeling co-training framework that adds auxiliary WM supervision to the same policy during RL, without changing the inference paradigm. To make auxiliary WM supervision informative and stable, PaW introduces three components: action-entropy-based WM data selection, noise-tolerant WM loss, and reward-adaptive loss balancing. Experiments on three agentic task benchmarks show consistent improvements over strong RL baselines across models and RL algorithms. These results suggest that standard RL rollouts are a practical source of WM supervision for language-agent training.