AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Zhangchen Xu, Junda Chen, Yue Huang, Dongfu Jiang, Jiefeng Chen, Hang Hua, Zijian Wu, Zheyuan Liu, Zexue He, Lichi Li, Shizhe Diao, Jiaxin Pei, Jinsung Yoon, Hao Zhang, Mengdi Wang, Radha Poovendran, Misha Sra, Alex Pentland, Zichen Chen
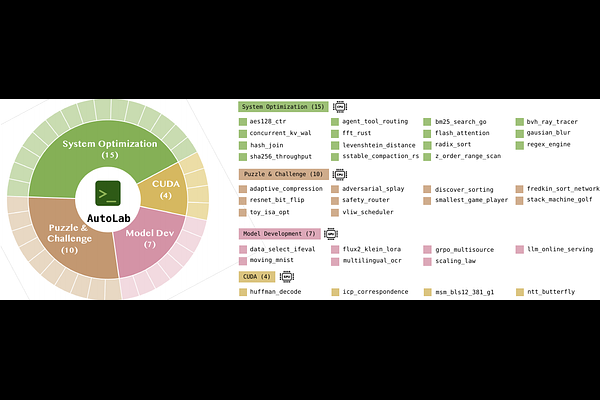
AbstractScientific and engineering progress is fundamentally a long-horizon iterative process: proposing changes, running experiments, measuring outcomes, and continuously refining artifacts. Yet existing benchmarks for frontier models primarily evaluate either single-turn responses or short-horizon agent trajectories, failing to capture the challenges of sustained iterative improvement over extended time horizons. To address this gap, we introduce AutoLab, a new benchmark for ultra long-horizon closed-loop optimization. AutoLab consists of 36 realistic, expert-curated tasks spanning four diverse domains: system optimization, puzzle & challenge, model development, and CUDA kernel optimization. Each task begins with a correct but deliberately suboptimal baseline and challenges agents to improve it within a strict wall-clock budget. Evaluating 17 state-of-the-art models reveals the dominant predictor of success is not the quality of an agent's initial attempt, but its persistence in repeatedly benchmarking, editing, and incorporating empirical feedback. While claude-opus-4.6 exhibits strong long-horizon optimization capabilities, most frontier models, including several proprietary ones, either terminate prematurely or exhaust their budgets with minimal progress. These results underscore the importance of time awareness and persistent iteration in autonomous agents. We open-source the full benchmark, evaluation harness, and task artifacts, to accelerate research toward truly capable long-horizon agents.