IG-Search: Step-Level Information Gain Rewards for Search-Augmented Reasoning
IG-Search: Step-Level Information Gain Rewards for Search-Augmented Reasoning
Zihan Liang, Yufei Ma, Ben Chen, Zhipeng Qian, Huangyu Dai, Lingtao Mao, Xuxin Zhang, Chenyi Lei, Wenwu Ou
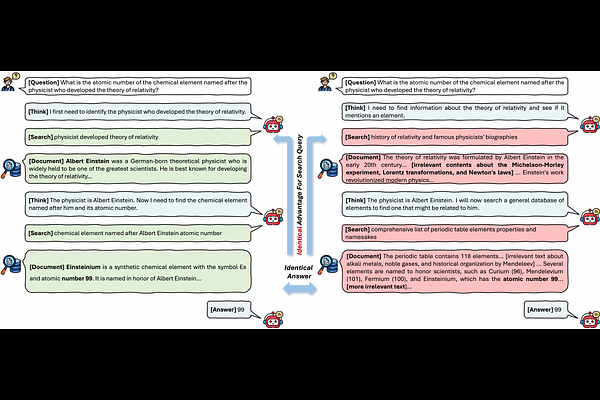
AbstractReinforcement learning has emerged as an effective paradigm for training large language models to perform search-augmented reasoning. However, existing approaches rely on trajectory-level rewards that cannot distinguish precise search queries from vague or redundant ones within a rollout group, and collapse to a near-zero gradient signal whenever every sampled trajectory fails. In this paper, we propose IG-Search, a reinforcement learning framework that introduces a step-level reward based on Information Gain (IG). For each search step, IG measures how much the retrieved documents improve the model's confidence in the gold answer relative to a counterfactual baseline of random documents, thereby reflecting the effectiveness of the underlying search query. This signal is fed back to the corresponding search-query tokens via per-token advantage modulation in GRPO, enabling fine-grained, step-level credit assignment within a rollout. Unlike prior step-level methods that require either externally annotated intermediate supervision or shared environment states across trajectories, IG-Search derives its signals from the policy's own generation probabilities, requiring no intermediate annotations beyond standard question-answer pairs. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate that IG-Search achieves an average EM of 0.430 with Qwen2.5-3B, outperforming the strongest trajectory-level baseline (MR-Search) by 1.6 points and the step-level method GiGPO by 0.9 points on average across benchmarks, with particularly pronounced gains on multi-hop reasoning tasks. Despite introducing a dense step-level signal, IG-Search adds only ~6.4% to per-step training wall-clock time over the trajectory-level baseline and leaves inference latency unchanged, while still providing a meaningful gradient signal even when every sampled trajectory answers incorrectly.