A Survey on Autonomy-Induced Security Risks in Large Model-Based Agents
A Survey on Autonomy-Induced Security Risks in Large Model-Based Agents
Hang Su, Jun Luo, Chang Liu, Xiao Yang, Yichi Zhang, Yinpeng Dong, Jun Zhu
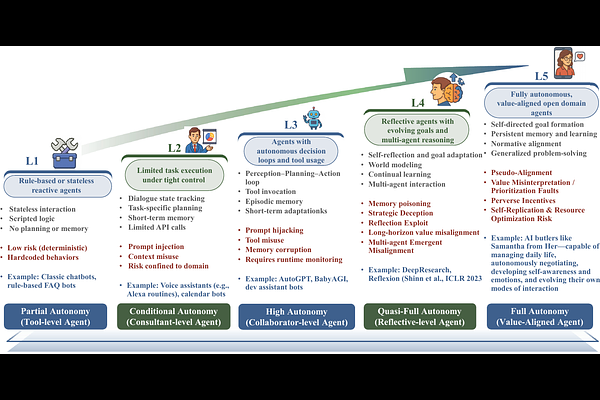
AbstractRecent advances in large language models (LLMs) have catalyzed the rise of autonomous AI agents capable of perceiving, reasoning, and acting in dynamic, open-ended environments. These large-model agents mark a paradigm shift from static inference systems to interactive, memory-augmented entities. While these capabilities significantly expand the functional scope of AI, they also introduce qualitatively novel security risks - such as memory poisoning, tool misuse, reward hacking, and emergent misalignment - that extend beyond the threat models of conventional systems or standalone LLMs. In this survey, we first examine the structural foundations and key capabilities that underpin increasing levels of agent autonomy, including long-term memory retention, modular tool use, recursive planning, and reflective reasoning. We then analyze the corresponding security vulnerabilities across the agent stack, identifying failure modes such as deferred decision hazards, irreversible tool chains, and deceptive behaviors arising from internal state drift or value misalignment. These risks are traced to architectural fragilities that emerge across perception, cognition, memory, and action modules. To address these challenges, we systematically review recent defense strategies deployed at different autonomy layers, including input sanitization, memory lifecycle control, constrained decision-making, structured tool invocation, and introspective reflection. We introduce the Reflective Risk-Aware Agent Architecture (R2A2), a unified cognitive framework grounded in Constrained Markov Decision Processes (CMDPs), which incorporates risk-aware world modeling, meta-policy adaptation, and joint reward-risk optimization to enable principled, proactive safety across the agent's decision-making loop.