AstroAlertBench: Evaluating the Accuracy, Reasoning, and Honesty of Multimodal LLMs in Astronomical Classification
AstroAlertBench: Evaluating the Accuracy, Reasoning, and Honesty of Multimodal LLMs in Astronomical Classification
Claire Chen, Jiabao Sean Xiao, Shuze Daniel Liu, Facundo Perez Paolino, Luke Handley, Theophile Jegou du Laz, Ricky Nilsson, Alice Zou, Matthew Graham, Ashish Mahabal
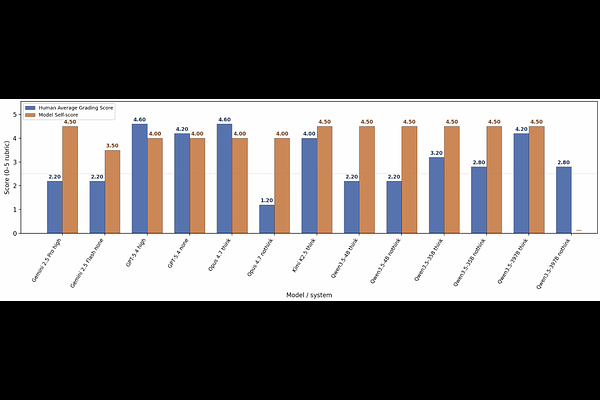
AbstractModern astronomical observatories generate a massive volume of multimodal data, creating a critical bottleneck for expert human review. While multimodal large language models (LLMs) have shown promise in interpreting complex visual and textual inputs, their ability to perform specialized scientific classification while providing interpretable reasoning remains understudied. We introduce AstroAlertBench, a comprehensive multimodal benchmark designed to evaluate LLM performance in astronomical event review along a three-stage logical chain: metadata grounding, scientific reasoning, and hierarchical classification over five categories. We use a pilot sample of 1,500 real-world alerts from the Zwicky Transient Facility (ZTF), a wide-field survey that scans the northern sky to detect transient astronomical events. On this dataset, we benchmark 13 frontier closed-source and open-weight LLMs that support visual input. Our results reveal that high accuracy does not always align with model ``honesty,'' defined as the ability to self-evaluate its reasoning, which affects its reliability as a real-world assistant. We further initialize a human-in-the-loop evaluation protocol as a precursor to future community-scale participation. Together, AstroAlertBench provides a framework for developing calibrated and interpretable astronomical assistants.