Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
Ali Behrouz, Farnoosh Hashemi, Vahab Mirrokni
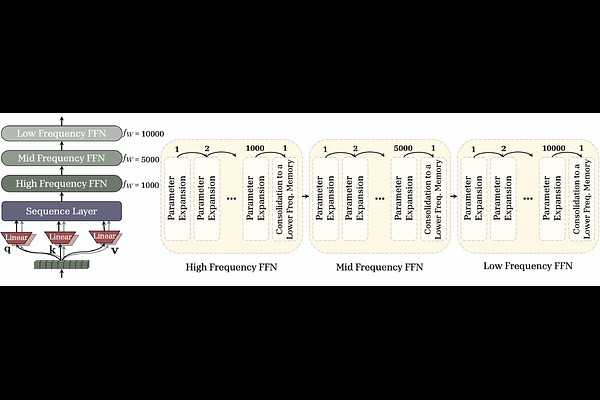
AbstractThe past few decades have witnessed significant advances in the design of machine learning algorithms, from early studies on task-specific shallow models to more general deep Large Language Models (LLMs). Despite showing promising results in tasks that require instant prediction or in-context learning, existing models lack the ability to continually learn and effectively transfer their temporal in-context knowledge to their long-term parameters. Inspired by human learning process, we introduce a ''Sleep'' paradigm that allows the models to continually learn, distill their short-term fragile memories into stable long-term knowledge with replay, and recursively improve themselves with ''Dreaming'' process. In more detail, sleep consists of two stages: (1) Memory Consolidation: an upward distillation process, called Knowledge Seeding, where the memories of a smaller-self are distilled into a larger network to provide more capacity while preserving the knowledge. As a proof of concept, we present a new Generalized Distillation process for {Knowledge Seeding} (i.e., the combination of on-policy distillation with Reinforcement Learning (RL)-based imitation learning); (2) Dreaming: a self-improvement phase, where the model uses RL to generate a curriculum of synthetic data to rehearse new knowledge and refine existing capabilities without human supervision. Our experiments on long-horizon, continual learning, knowledge incorporation, and few-shot generalization tasks support the importance of the sleep stage.