Beyond Scaling Curves: Internal Dynamics of Neural Networks Through the NTK Lens
Beyond Scaling Curves: Internal Dynamics of Neural Networks Through the NTK Lens
Konstantin Nikolaou, Sven Krippendorf, Samuel Tovey, Christian Holm
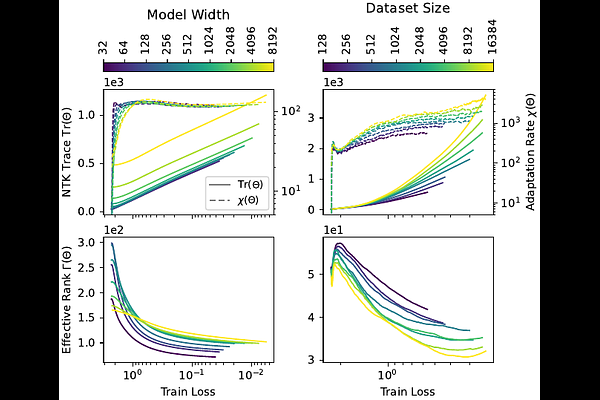
AbstractScaling laws offer valuable insights into the relationship between neural network performance and computational cost, yet their underlying mechanisms remain poorly understood. In this work, we empirically analyze how neural networks behave under data and model scaling through the lens of the neural tangent kernel (NTK). This analysis establishes a link between performance scaling and the internal dynamics of neural networks. Our findings of standard vision tasks show that similar performance scaling exponents can occur even though the internal model dynamics show opposite behavior. This demonstrates that performance scaling alone is insufficient for understanding the underlying mechanisms of neural networks. We also address a previously unresolved issue in neural scaling: how convergence to the infinite-width limit affects scaling behavior in finite-width models. To this end, we investigate how feature learning is lost as the model width increases and quantify the transition between kernel-driven and feature-driven scaling regimes. We identify the maximum model width that supports feature learning, which, in our setups, we find to be more than ten times smaller than typical large language model widths.