A flaw in using pre-trained pLLMs in protein-protein interaction inference models
A flaw in using pre-trained pLLMs in protein-protein interaction inference models
Szymborski, J.; Emad, A.
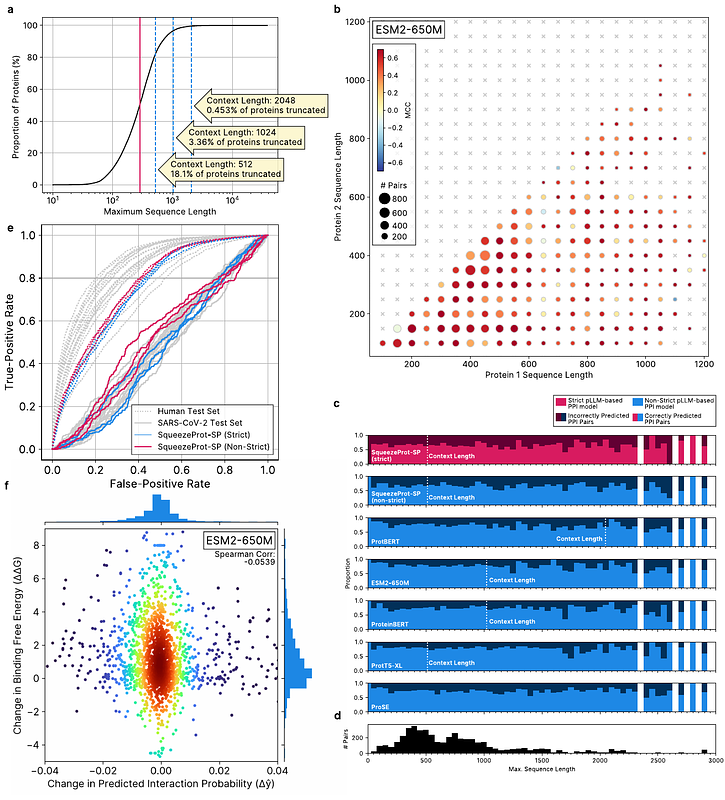
AbstractWith the growing pervasiveness of pre-trained protein large language models (pLLMs), pLLM-based methods are increasingly being put forward for the protein-protein interaction (PPI) inference task. Here, we identify and confirm that existing pre-trained pLLMs are a source of data leakage for the downstream PPI task. We characterize the extent of the data leakage problem by training and comparing small and efficient pLLMs on a dataset that controls for data leakage (\'\'strict\'\') with one that does not (\'\'non-strict\'\'). While data leakage from pre-trained pLLMs cause measurable inflation of testing scores, we find that this does not necessarily extend to other, non-paired biological tasks such as protein keyword annotation. Further, we find no connection between the context-lengths of pLLMs and the performance of pLLM-based PPI inference methods on proteins with sequence lengths that surpass it. Furthermore, we show that pLLM-based and non-pLLM-based models fail to generalize in tasks such as prediction of the human-SARS-CoV-2 PPIs or the effect of point mutations on binding-affinities. This study demonstrates the importance of extending existing protocols for the evaluation of pLLM-based models applied to paired biological datasets and identifies areas of weakness of current pLLM models. With the growing pervasiveness of pre-trained protein large language models (pLLMs), pLLM-based methods are increasingly being put forward for the protein-protein interaction (PPI) inference task. Here, we identify and confirm that existing pre-trained pLLMs are a source of data leakage for the downstream PPI task. We characterize the extent of the data leakage problem by training and comparing small and efficient pLLMs on a dataset that controls for data leakage (``strict\'\') with one that does not (``non-strict\'\'). While data leakage from pre-trained pLLMs cause measurable inflation of testing scores, we find that this does not necessarily extend to other, non-paired biological tasks such as protein keyword annotation. Further, we find no connection between the context-lengths of pLLMs and the performance of pLLM-based PPI inference methods on proteins with sequence lengths that surpass it. Furthermore, we show that pLLM-based and non-pLLM-based models fail to generalize in tasks such as prediction of the human-SARS-CoV-2 PPIs or the effect of point mutations on binding-affinities. This study demonstrates the importance of extending existing protocols for the evaluation of pLLM-based models applied to paired biological datasets and identifies areas of weakness of current pLLM models.