Assembling unmapped reads reveals hidden variation in South Asian genomes
Assembling unmapped reads reveals hidden variation in South Asian genomes
Das, A.; Biddanda, A.; McCoy, R. C.; Schatz, M.
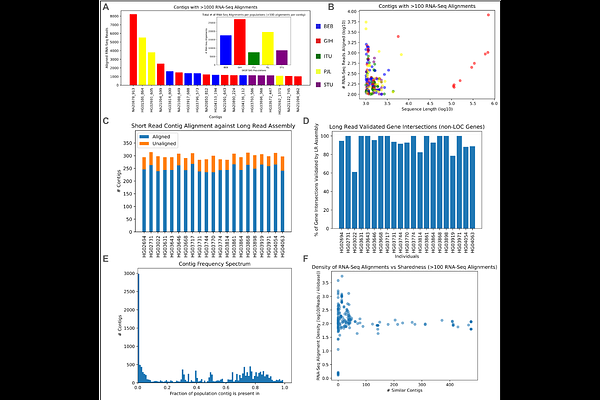
AbstractConventional genome mapping-based approaches systematically miss genetic variation, particularly in regions that substantially differ from the reference. To explore this hidden variation, we examined unmapped and poorly mapped reads from the genomes of 640 human individuals from South Asian (SAS) populations in the 1000 Genomes Project and the Simons Genome Diversity Project. We assembled tens of megabases of non-redundant sequence in tens of thousands of large contigs, much of which is present in both SAS and non-SAS populations. We demonstrated that much of this sequence is not discovered by traditional variant discovery approaches even when using complete genomes and pangenomes. Across 20,000 placed contigs, we found 8,215 intersections with 106 protein coding genes and >15,000 placements within 1 kbp of a known GWAS hit. We used long read data from a subset of samples to validate the majority of their assembled sequences, aligned RNA-seq data to identify hundreds of unplaced contigs with transcriptional potential, and queried existing nucleotide databases to evaluate the origins of the remaining unplaced sequences. Our results highlight the limitations of even the most complete reference genomes and provide a model for understanding the distribution of hidden variation in any human population.