Super Bloom: Fast and precise filter for streaming k-mer queries
Super Bloom: Fast and precise filter for streaming k-mer queries
Conchon-Kerjan, E.; Rouze, T.; Robidou, L.; Ingels, F.; Limasset, A.
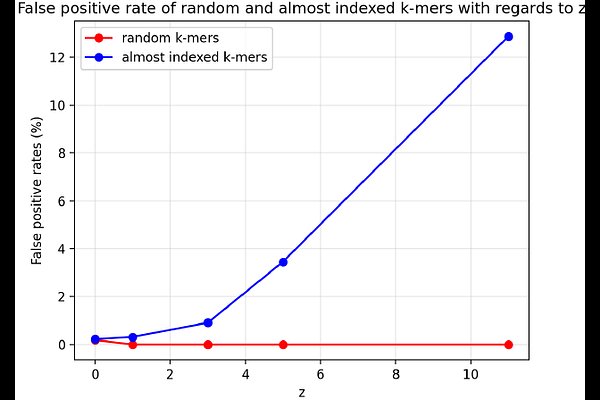
AbstractApproximate membership query structures are used throughout sequence bioinformatics, from read screening and metagenomic classification to assembly, indexing, and error correction. Among them, Bloom filters remain the default choice. They are not the most efficient structures in either time or memory, but they provide an effective compromise between compactness, speed, simplicity, and dynamic insertions, which explains their widespread adoption in practice. Their main drawback is poor cache locality, since each query typically requires several random memory accesses. Blocked Bloom filters alleviate this issue by restricting accesses for any given element to a single memory block, but this usually comes with a loss in accuracy at fixed memory. In this work, we introduce the Super Bloom Filter, a Bloom filter variant designed for streaming k-mer queries on biological sequences. Super Bloom uses minimizers to group adjacent k-mers into super-k-mers and assigns all k-mers of a group to the same memory block, thereby amortizing random accesses over consecutive k-mer queries and improving cache efficiency. We further combine this layout with the findere scheme, which reduces false positives by requiring consistent evidence across overlapping subwords. We provide a theoretical analysis of the construction of Super Bloom filters, showing how minimizer density controls the expected reduction in memory transfers, and derive a practical parameterization strategy linking memory budget, block size, collision overhead, and the number of hash functions to robust false-positive control. Across a broad range of memory budgets and numbers of hash functions, Super Bloom consistently outperforms existing Bloom filter implementations, with several-fold time improvements. As a practical validation, we integrated it into a Rust reimplementation of BioBloom Tools, a sequence screening tool that builds filters from reference genomes and classifies reads through k-mer membership queries for applications such as host removal and contamination filtering. This replacement yields substantially faster indexing and querying than both the original C++ implementation and Rust variants based on Bloom filters and blocked Bloom filters. The findere scheme also reduces false positives by several orders of magnitude, with some configurations yielding no observed false positives among 10^9 random queried k-mers. Code is available at https://github.com/EtienneC-K/SuperBloom and https://github.com/Malfoy/SBB